
Распознаванием лиц и предметов на фото нынче никого не удивишь. Однако не всегда понятно как строятся такого рода продукты не в теории, а на практике. Пришла идея реализовать программу, которая бы распознавала конкретный предмет на фото или видео.
Инструментов для таких целей довольно много. В зависимости от того где и как должно работать приложение, зависит выбор подхода. Отрасль весьма обширная, каждый год появляется много всего. Например для работы в мобильных приложениях или на компьютере рекомендуют разные оптимизированные библиотеки. Из материалов, что я нашел, чаще всего выделяются tensorflow и openCV. Попробуем разобраться с openCV для Python.
Библиотека openCV
Данная библиотека предоставляет обширный набор инструментов для работы с фото и видео, а так же она дает возможность работать с алгоритмами компьютерного зрения.
OpenCV разрабатывается уже довольно давно. Первый релиз на их сайте датируется 4 июля 2011 года, однако можно найти информацию и о более ранних версиях из середины нулевых.
Установка библиотеки для Python
Тут все как обычно
pip install opencv-python
Тут у меня возникла не большая проблема, IDE не хотело видеть методы библиотеки. Для того что бы это пофиксить, я скопировал файл из папки …\venv\Lib\site-packages\cv2\cv2.pyd в папку …\venv\Lib\site-packages\cv2.pyd. После переиндексации проблема решилась.
Работа с изображениями
В библиотеке множество инструментов для редактирования изображения. Зачастую перед запуском алгоритма, нужно подготовить фото, например некоторые методы на вход требуют определенный формат изображения.
Итак, мы можем менять тип фото, например с RGB на gray (и другие). Искать углы изображения. Отображать вертикально или горизонтально. Есть возможность сделать пропорциональный ресайз. Так же мы можем работать со слоями (расчленить RGB на R, G и B и затем склеивать их как захочется или оставить только один слой). Можем создавать негатив фото. Список можно продолжать долго.
Пару примеров.
Найдем «углы» изображения
|
1 2 3 4 5 6 7 |
import cv2 img = cv2.imread('images/5.jpg') gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) img = cv2.Canny(gray, 100, 100) cv2.imshow('test', img) cv2.waitKey(0) |
Вот какой мы получим результат
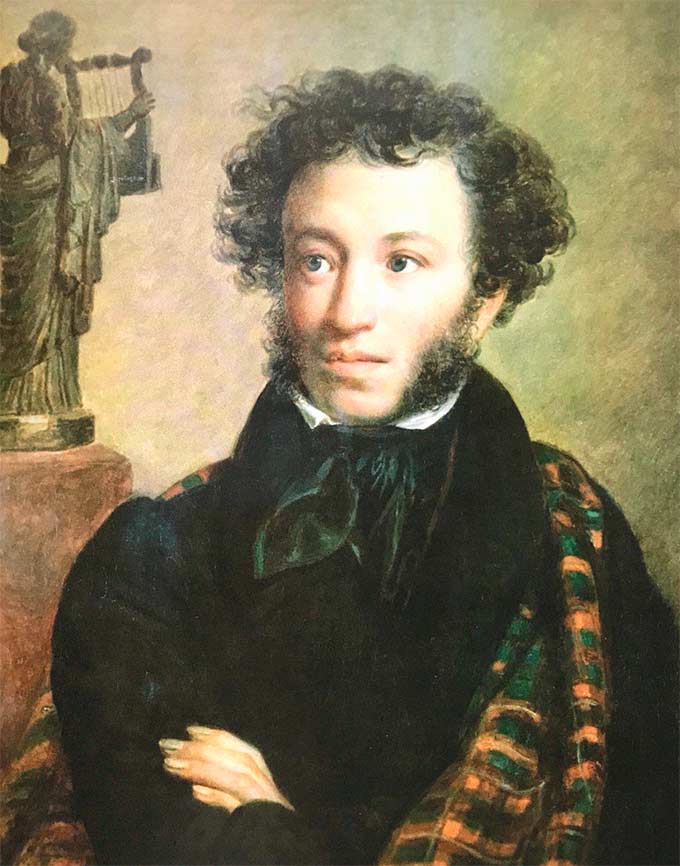

Разница в этих двух картинках, по мимо визуальной, заключается в том, что бы картинку слева представить для восприятия алгоритмов нужно для каждого пикселя 3 переменных, т.е. в формате RGB (0-255, 0-255, 0-255), а картинка справа является бинарной. т.е. 0 — пиксель белый, 1 — пиксель черный. В теории это может быть полезно для производительности.
В коде выше так же показан пример преобразования RGB в GRAY при помощи метода cvtColor(). Так же стоит обратить внимание на параметры метода Canny(img, 100, 100). Цифры 100, 100 в данном случаи это точность, их изменение будет значительно менять изображение. По сути это порог, который обрезает серый фон в формате 0-255.
С преобразованной картинкой справа так же можно работать, например следующим кодом.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
import cv2 import numpy as np img = cv2.imread('images/pushkin.jpg') gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) img = cv2.Canny(gray, 100, 100) kernel = np.ones((5, 5), np.uint8) img = cv2.dilate(img, kernel, iterations=1) img = cv2.erode(img, kernel, iterations=1) cv2.imshow('test', img) cv2.waitKey(0) |
Здесь вокруг каждого замкнутого контура проводится линия, а затем эта линия затирается. Важным параметром тут является iterations в методах dilate() и ercode(). Так же обратите внимание, что тут присутствует библиотека nump. Конкретно в этом примере она используется для создания массива единиц размером 5х5. Как я писал немного выше, в бинарном понятии изображения, это черное полотно. Все пиксели черные(1).
Результат скрипта

Считается, что в некоторых случаях такие преобразования могут быть полезны для работы алгоритмов компьютерного зрения.
Далее попробуем разбить изображение на слои и потом склеить их в другом порядке.
|
1 2 3 4 5 6 7 8 |
import cv2 img = cv2.imread('images/pushkin.jpg') b, g, r = cv2.split(img) img = cv2.merge([r, b, g]) cv2.imshow('test', img) cv2.waitKey(0) |

В итоге мы получили эффект «маски», так же может быть полезно в некоторых случаях.
Больше методов для работы с изображениями можно посмотреть в документации.
Поиск предметов на изображениях. Каскад Хаара
Каскад Хаара представляет собой простой классификатор. Это один из первых алгоритмов, позволяющий находит лица на видео в реальном времени. Более подробно об этом рекомендую почитать в других статьях.
Для того что бы лучше понять о чем пойдет речь, есть отличное видео, которое показывает как примерно происходит детекция «под капотом».
Попробуем сделать нечто подобное с использованием библиотеки openCV.
Первым делом нам необходима обученная модель, тут она представляет собой xml файл с весами. Разработчики библиотеки положили некоторые обученные модели и мы можем ими воспользоваться. Что бы их найти нужно пройти по пути …\venv\Lib\site-packages\cv2\data
Для удобства я скопировал нужный xml файл себе в отдельную папку tools в проекте. Далее пишем следующий код.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
import cv2 face_detection = cv2.CascadeClassifier('tools/haarcascade_frontalface_default.xml') img = cv2.imread('images/pushkin.jpg') gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) faces = face_detection.detectMultiScale(gray, scaleFactor=1.4, minNeighbors=5) for (x, y, w, h) in faces: img = cv2.rectangle(img, (x, y), (x + w, y + h), (255, 0, 0), 2) cv2.imshow('test', img) cv2.waitKey(0) |
Как видите, я использовал haarcascade_frontalface_default.xml, эта модель ищет нам лица. Если мы попробуем применить ее к нашему изображению, то получим следующий результат

В методе detectMultiScale есть важные параметры(не обязательные). scaleFactor — это множитель того, на сколько отличается размер искомого предмета на нашем изображении от того, что было использовано во время обучения модели. Должен обязательно быть больше 1. minNeighbors — параметр описывает сколько должно быть найдено прямоугольников на искомом предмете (что бы понять о чем идет речь, посмотрите видео выше). Метод rectangle рисует на изображении прямоугольник по возвращенным координатам. В качестве параметров принимает изображение, координаты, код цвета и уровень толщины линии.
Попробуем пример по сложнее (рандомное фото из интернета)
{kind=link}
Как видите, метод работает довольно точно. По мимо этого библиотека предоставляет модели по поиску глаз, номеров машин, людей в полный рост, животных и т.д.
Например найдем котов на фото. В коде меняем считывание классификатора на haarcascade_frontalcatface.xml

В заключении этого блока еще хотел бы отметить один момент. В приведенных сниппетах приведены примеры отображения изображения непосредственно во время работы программы. Для того что бы сохранить изображение нужно заменить строку cv2.imshow(‘test’, img) на cv2.imwrite(‘output/img_name.jpg’, img)
Обучаем модель для поиска своего предмета на фото или видео.
Библиотека предоставляет широкий спектр инструментов. Однако для какой-то прикладной задачи нам может не хватить того что уже есть. Поэтому попробуем натренировать свою модель для поиска нужного нам предмета. В качестве такого предмета я выбрал кружку.
Подготовка софта
Софт для тренировки нужно качать отдельно. Переходим по ссылке. выберем версию не выше 3.Х. Я использовал opencv-3.4.16-vc14_vc15.
После разархивации файлов в папке, нам нужно обратить внимание на утилиты, которые будут участвовать в процессе обучения.
У меня этот путь к утилитам выглядит так E:\CodeContent\libs\opencv\build\x64\vc15\bin
Тут нас интересует opencv_createsamples.exe и opencv_traincascade.exe Пока ничего не нужно запускать, переходим к следующему этапу.
Подготовка дата сета
Самым простым вариантом подготовки дата сета мне показался способ со съемкой. Нам необходимо отснять на видео предмет с разных ракурсов. Постараться сделать так, что бы предмет всегда был во всем кадре. Можно это правило и не соблюдать, но тогда придется сильно заморачиваться с разметкой.
Итак, я решил что буду детектить кружку. Отсняв минутное видео, при помощи библиотеки openCV начинаем делать дата сет.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
cap = cv2.VideoCapture('video/init_cap.MOV') iter = 1 while True: sucess, img = cap.read() gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) gray = gray[150:650, 100:600] gray = cv2.resize(gray, (364, 500)) cv2.imwrite('data/Good/' + str(iter) + '.jpg', gray) iter += 1 fl = cv2.flip(gray, 1) cv2.imwrite('data/Good/' + str(iter) + '.jpg', fl) iter += 1 if cv2.waitKey(1) & 0xFF == ord('q'): break |
Итак init_cap.MOV это наше видео. Затем мы берем каждый кадр из этого видео, переводим его в серый, отрезаем лишнее, немного меняем его размер пишем в папку, отображаем кадр зеркально и пишем еще раз. Как итог я получил 2000+ фото.
Выборка почти готова, правда скорее всего там есть не удачные кадры. Я бы рекомендовал удалить в ручную все фото, где нужный Вам предмет не занимает весь кадр. После удаления всего лишнего переименуем файлы при помощи следующего кода.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
folder = r'E:\CodeContent\Python\OpenCVStart\data\Good\\' count = 1 for file_name in os.listdir(folder): source = folder + file_name destination = folder + str(count) + ".jpg" print('Good\\' + str(count) + ".jpg" + ' 1 0 0 364 500') # print('Bad\\' + str(count) + ".jpg") os.rename(source, destination) count += 1 # verify the result res = os.listdir(folder) print(res) |
По мимо этого в консоль выведется нужный нам список всех имеющихся у нас файлов. После этого необходимо создать файл Good.dat и вставить в него то что вывелось в консоли.
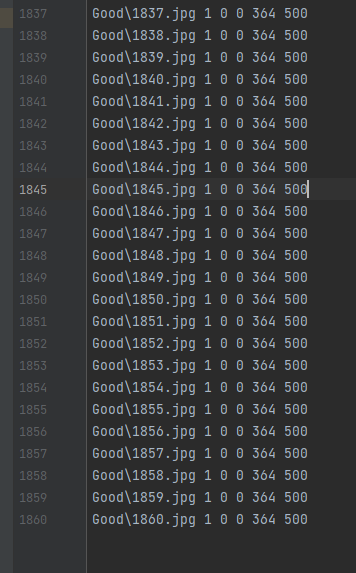
У меня получился такой файл. Тут после пути к файлу идет цифра 1. Это количество нужных нам предметов на фото. Число может быть больше единицы, но тогда должно быть описано больше координат. Как это делается, если понадобится, смотрите в документации. Затем идут цифры координат предмета на фото, т.к. я использовал подход что в каждое фото это по сути наш предмет полностью, то идут сначала 0 0(это верхняя левая точка) и 364 500(разрешение моих фото).
Вот так после всех манипуляций выглядит мой сет положительных примеров (всего 1860 фото).

Примерно то же самое нужно сделать для негативного дата сета. Это должны быть любые фото, где НЕТ нашего искомого предмета. Можно подойти с тем же подходом как и к позитивному сету т.е. наснимать интерьер и на генерировать фото. Эти фото нужно поместить в тот же каталог в папку с условным названием Bad. У меня вышло 1821 фото.
Создаем файл Bad.dat, тут просто прописываем путь к нашим файлам без указания каких либо координат.
Тренировка своей модели
Итак, после подготовки у нас должны быть 2 папки и 2 файла. Добавим сюда еще одну папку, в ней у нас в итоге будет храниться XML файл. Назову ее result
Должна быть такая картина
На этом этапе нам нужно воспользоваться opencv_createsamples.exe. Открываем консоль в папке с нашими сетами и вводим следующую команду.
E:\CodeContent\libs\opencv\build\x64\vc15\bin\opencv_createsamples.exe -info Good.dat -vec samples.vec -w 15 -h 20 -num 1800
Путь к утилите я прописал абсолютный.
У нас в папке должен появиться файл samples.vec, а в консоли выведется что-то подобное
Немного по параметрам
- info — наш конфигурационный файл с описанием положительного сета
- vec — имя файла, который у нас должен сгенерироваться
- w — width относительная ширина искомого предмета
- h — hight относительная высота искомого предмета (т.к. кружка по пропорциям по сути прямоугольник, я поставил 15х20)
- num — количество положительных фото, которые у Вас есть. По умолчанию это значение 1000
Теперь можно запускать тренировку, используя утилиту opencv_traincascade.exe. Вводим примерно следующую команду в этой же консоли.
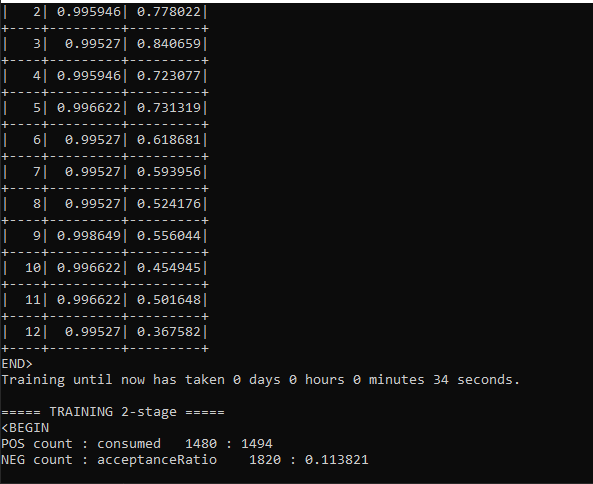
E:\CodeContent\libs\opencv\build\x64\vc15\bin\opencv_traincascade.exe -data result -vec samples.vec -bg Bad.dat -numStages 25 -minhitrate 0.999 -maxFalseAlarmRate 0.4 -numPos 1480 -numNeg 1820 -w 15 -h 20 -mode ALL -precalcValBufSize 6024 -precalcIdxBufSize 6024
Консоль начинает выводить листинг работы
По параметрам
- data — название папки, куда будем сохранять результат
- vec — файл, созданный на предыдущем шаге
- bg — текстовый файл, описывающий негативный дата сет
- numStages — количество итераций, обычно рекомендуют делать не меньше 15
- minhitrate — минимальный показатель попаданий, сильно занижать эту цифру не рекомендуется
- maxFalseAlarmRate — показатель ложных срабатываний
- numPos — количество фото в папке Good, минус примерно 20%. Считается что 20% дата сета могут иметь ошибки. Не иметь ценности для обучения либо иметь не правильную разметку.
- numNeg — количество фото из папки Bad
- w , h — высота и ширина условного искомого предмета, пишем те же значения, что и на предыдущем шаге
- precalcValBufSize, precalcIdxBufSize — количество выделяемой оперативной памяти компьютера на процесс обучения
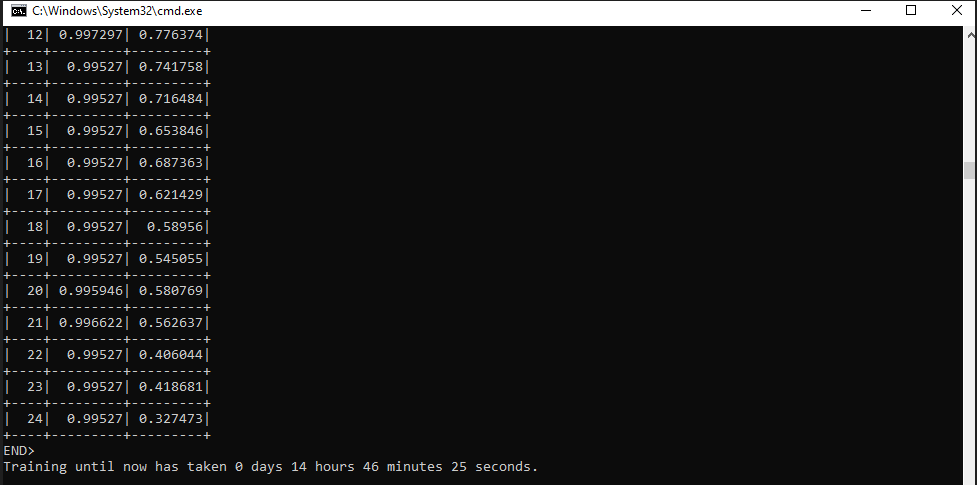
Конец обучения, как видите на 25 итераций у меня ушло 14+ часов
Зайдя в папку result, мы обнаружим следующие файлы
cascade.xml как раз то что нам и нужно.
Результат
Если мы подставим наш получившийся xml файл в код выше, где мы искали лица, то получается следующий результат.

Как видно, работает. Теперь сделаем то же самое для видео. Скидываем заготовленный видеоролик в папку откуда будем его считывать (либо еще можно воспользоваться веб камерой), затем пишем следующий код.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
import cv2 detection = cv2.CascadeClassifier('data/result/cascade.xml') out = cv2.VideoWriter('video/result_video.avi', cv2.VideoWriter_fourcc(*'DIVX'), 30, (464, 848)) cap = cv2.VideoCapture('video/cap_video.MOV') while True: sucess, img = cap.read() caps = detection.detectMultiScale(img, scaleFactor=1.1, minNeighbors=2) for (x, y, w, h) in faces: img = cv2.rectangle(img, (x, y), (x + w, y + h), (255, 0, 0), 3) out.write(img) cv2.imshow('Show', img) if cv2.waitKey(1) & 0xFF == ord('q'): break out.release() |
В итоге у меня получилось видео с результатом роботы натренированной модели.
На ролике видны мерцания, я думаю от них можно избавиться, если заняться рутинной разметкой датасета, сделать ее более репрезентативной, и более глубоко по изучать параметры утилиты для запуска тренировки модели. Однако точно можно сказать что модель работает, кружка отмечается в видеопотоке с низким процентом ошибок.